
Татьяна Ефимова предлагает статью на тему: "параметры уравнения парной регрессии" с детальным описанием.
Содержание
Расчет параметров линейной парной регрессии
Читайте также:
- II. 3. 0 Расчет буроинъекционных свай по несущей способности.
- II. ТЕХНИКО-ЭКОНОМИЧЕСКИЕ РАСЧЕТЫ В ЭЛЕКТРОСНАБЖЕНИИ
- III. Расчет чистого дохода, направляемого на неотложные выплаты
- А. Расчет производственного допуска.
- Абсолютные и относительные величины в статистике. Их виды и методика расчета.
- Абсолютные показатели вариации и методы их расчета
- Аккредитивная форма расчетов
- Алгоритм 1. Расчет параметров уравнения линейной регрессии и проверки адекватности модели исходным данным
- Алгоритм 1.1. Расчет описательных статистик
- Алгоритм 2.1. Расчет внутригрупповых дисперсий результативного признака
- Алгоритм расчета коэффициента ранговой корреляции Спирмена rs.
- Алгоритм расчета критерия Колмогорова-Смирнова.
Регрессионный анализ, его цель и назначение
Общее представление о корреляционно-регрессивном анализе
Существующие между явлениями формы и виды связей весьма разнообразны по своей классификации. Предметом статистики являются только такие из них, которые имеют количественный характер и изучаются с помощью количественных методов. Рассмотрим метод корреляционно-регрессионного анализа, который является основным в изучении взаимосвязей явлений.
Данный метод содержит две свои составляющие части — корреляционный анализ и регрессионный анализ. Корреляционный анализ — это количественный метод определения тесноты и направления взаимосвязи между выборочными переменными величинами. Регрессионный анализ — это количественный метод определения вида математической функции в причинно-следственной зависимости между переменными величинами.
Для оценки силы связи в теории корреляции применяется шкала английского статистика Чеддока: слабая — от 0,1 до 0,3; умеренная — от 0,3 до 0,5; заметная — от 0,5 до 0,7; высокая — от 0,7 до 0,9; весьма высокая (сильная) — от 0,9 до 1,0. Она используется далее в примерах по теме.
Регрессионный анализ — это статистический метод исследования зависимости случайной величины у от переменных (аргументов) хj (j = 1, 2. k),рассматриваемых в регрессионном анализе как неслучайные величины независимо от истинного закона распределения xj.
Обычно предполагается, что случайная величина у имеет нормальный закон распределения с условным математическим ожиданием 
= φ(x1, . хk),являющимся функцией от аргументов хj и с постоянной, не зависящей от аргументов дисперсией σ2.
Для проведения регрессионного анализа из (k + 1)-мерной генеральной совокупности (у, x1, х2, . хj, . хk) берется выборка объемом n, и каждое i-е наблюдение (объект) характеризуется значениями переменных (уi, xi1, хi2, . хij, . xik), где хij — значение j-й переменной для i-го наблюдения (i = 1, 2. n), уi— значение результативного признака для i-го наблюдения.
Наиболее часто используемая множественная линейная модель регрессионного анализа имеет вид

(53.8)
где βj — параметры регрессионной модели;
εj — случайные ошибки наблюдения, не зависимые друг от друга, имеют нулевую среднюю и дисперсию σ2.
Отметим, что модель (53.8) справедлива для всех i = 1,2, . n, линейна относительно неизвестных параметров β0, β1,…, βj, …, βk и аргументов.
Как следует из (53.8), коэффициент регрессии Bj показывает, на какую величину в среднем изменится результативный признак у, если переменную хjувеличить на единицу измерения, т.е. является нормативным коэффициентом.
В матричной форме регрессионная модель имеет вид

(53.9)
где Y — случайный вектор-столбец размерности п х 1 наблюдаемых значений результативного признака (у1, у2. уn); Х— матрица размерности п х (k + 1) наблюдаемых значений аргументов, элемент матрицы х,, рассматривается как неслучайная величина (i = 1, 2, . n; j=0,1, . k; x0i, = 1); β — вектор-столбец размерности (k + 1) х 1 неизвестных, подлежащих оценке параметров модели (коэффициентов регрессии); ε — случайный вектор-столбец размерности п х 1 ошибок наблюдений (остатков). Компоненты вектора εi не зависимы друг от друга, имеют нормальный закон распределения с нулевым математическим ожиданием (Mεi = 0) и неизвестной постоянной σ2 (Dεi = σ2).
На практике рекомендуется, чтобы значение п превышало k не менее чем в три раза.
парная – регрессия между двумя переменными у и x, т. е, модель вида: у = f (x) + Е, где у -зависимая переменная (результативный признак), x – независимая, объясняющая переменная (признак – фактор), Е – возмущение, или стохастическая переменная, включающая влияние неучтенных факторов в модели.
В случае парной линейной зависимости строится регрессионная модель по уравнению линейной регрессии. Параметры этого уравнения оцениваются с помощью процедур, наибольшее распространение получил метод наименьших квадратов.
Метод наименьших квадратов (МНК) – метод оценивания параметров линейной регрессии, минимизирующий сумму квадратов отклонений наблюдений зависимой переменной от искомой линейной функции.

где уi– статические значения зависимой переменной; f (х) – теоретические значения зависимой переменной, рассчитанные с помощью уравнения регрессии.
Экономический смысл параметров уравнения линейной парной регрессии. Параметр b показывает среднее изменение результата у с изменением фактора х на единицу. Параметр а = у, когда х = 0. Если х не может быть равен 0, то а не имеет экономического смысла. Интерпретировать можно только знак при а: если а > 0. то относительное изменение результата происходит медленнее, чем изменение фактора, т. е. вариация результата меньше вариации фактора: V
Дата добавления: 2015-04-24 ; Просмотров: 2184 ; Нарушение авторских прав? ;
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Линейная парная регрессия (стр. 1 из 4)
1. Линейная парная регрессия
Корреляционная зависимость может быть представлена в виде
В регрессионном анализе рассматривается односторонняя зависимость случайной переменной Y от одной (или нескольких) неслучайной независимой переменной Х . Такая зависимость Y от X (иногда ее называют регрессионной ) может быть также представлена в виде модельного уравнения регрессии Y от X (1). При этом зависимую переменную Y называют также функцией отклика (объясняемой, выходной, результирующей, эндогенной переменной, результативным признаком), а независимую переменную Х – объясняющей (входной, предсказывающей, предикторной, экзогенной переменной, фактором, регрессором, факторным признаком).
Для точного описания уравнения регрессии необходимо знать условный закон распределения зависимой переменной Y при условии, что переменная Х примет значение х , т.е. Х = х . В статистической практике такую информацию получить, как правило, не удается, так как обычно исследователь располагает лишь выборкой пар значений (xi , yi ) ограниченного объема n . В этом случае речь может идти об оценке (приближенном выражении, аппроксимации) по выборке функции регрессии. Такой оценкой является выборочная линия (кривая) регрессии :
Уравнение (2) называется выборочным уравнением регрессии .
В дальнейшем рассмотрим линейную модель и представим ее в виде
Для решения поставленной задачи определим формулы расчета неизвестных параметров уравнения линейной регрессии (b , b 1 ).
Согласно методу наименьших квадратов (МНК) неизвестные параметры b и b 1 выбираются таким образом, чтобы сумма квадратов отклонений эмпирических значенийyi от значений
На основании необходимого условия экстремума функции двух переменных S = S (b , b 1 ) (4) приравняем к нулю ее частные производные, т.е.

откуда после преобразований получим систему нормальных уравнений для определения параметров линейной регрессии:
Теперь, разделив обе части уравнений (5) на n , получим систему нормальных уравнений в следующем виде:
где соответствующие средние определяются по формулам:
Решая систему (6), найдем
Коэффициент b 1 называется выборочным коэффициентом регрессии Y по X .
Коэффициент регрессии Y по X показывает, на сколько единиц в среднем изменяется переменная Y при увеличении переменной X на одну единицу.
Отметим, что из уравнения регрессии
На первый взгляд, подходящим измерителем тесноты связи Y от Х является коэффициент регрессии b 1 . Однако b 1 зависит от единиц измерения переменных. Очевидно, что для “исправления” b 1 как показателя тесноты связи нужна такая стандартная система единиц измерения, в которой данные по различным характеристикам оказались бы сравнимы между собой. Если представить уравнение
В этой системе величина
Если r > 0 (b 1 > 0), то корреляционная связь между переменными называется прямой, если r 2 . (20)
4. Возмущения ei и ej не коррелированны:
5. Возмущения ei есть нормально распределенная случайная величина.
Оценкой модели (18) по выборке является уравнение регрессии
Теорема Гаусса – Маркова . Если регрессионная модель
yi = b + b1xi + ei удовлетворяет предпосылкам 1-5, то оценкиb , b 1 имеют наименьшую дисперсию в классе всех линейных несмещенных оценок.
Таким образом, оценки b и b 1 в определенном смысле являются наиболее эффективными линейными оценками параметров b и b1 .
Проверить значимость уравнения регрессии – значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включенных в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной. Для проверки значимости выдвигают нулевую гипотезу о надежности параметров. Вспомним основные понятия и определения необходимые для анализа значимости параметров регрессии.
Статистическая гипотеза – это предположение о свойствах случайных величин или событий, которое мы хотим проверить по имеющимся данным.
Пример расчета параметров парной линейной регрессии
В таблице 1.3 приведены данные о доле в расходах, направленной на потребление продуктов питания и заработной плате по нескольким регионам Уральского Федерального округа. Так как заработная плата характеризует одну из статей доходов домохозяйств, причем основную, а доля расходов на потребление продуктов питания – основную статью расходов, эти два показателя должны быть связаны между собой.
Х – заработная плата, тыс. руб.;
У – доля расходов на потребление продуктов питания, так как доля расходов зависит от заработной платы, %.
Задание: 1) параметризация: подобрать уравнение связи;
2) идентификация: идентифицировать параметры уравнения, измерить тесноту связи между фактором и результатом;
3) верификация: оценить надежность модели, сделать выводы;
– оценить уровень потребления при заданной заработной плате 58,0 млн.руб.
– оценить уровень потребления при заданной заработной плате равной ( 
+5%).
Порядок решения:
1) Параметризация: выберем для подбора параметров уравнение парной линейной регрессии, как получившее наибольшее распространение, наиболее легко идентифицируемое и интерпретируемое. Общий вид уравнения парной линейной регрессии в соответствии с формулой (4) следующий:
2) На этапе идентификации необходимо вместо буквенных обозначений параметров а и b найти числа, соответствующие данной парной регрессии.
Найдем параметры а и b по формулам (7) и (8). Все предварительные расчеты приведены в таблице 3.
Таблица 1.3 – исходные данные для расчетов
| № п/п | Х, млн. руб | Y, % | Y·Х | Y 2 | Х 2 | ŶХ | Y-ŶХ | (Y-Ŷ) 2 | 10 = |8/7| | (Х- ) 2 |
| 68,8 | 45,1 | 3102,9 | 2034,0 | 4733,4 | 51,0 | -5,9 | 34,4 | 0,115 | 119,1 | |
| 61,2 | 59,0 | 3610,8 | 3481,0 | 3745,4 | 53,7 | 5,3 | 28,0 | 0,099 | 11,0 | |
| 59,9 | 57,2 | 3426,3 | 3271,8 | 3588,0 | 54,2 | 3,0 | 9,2 | 0,056 | 4,1 | |
| 56,7 | 61,8 | 3504,1 | 3819,2 | 3214,9 | 55,3 | 6,5 | 41,9 | 0,117 | 1,4 | |
| 55,0 | 58,8 | 3234,0 | 3457,4 | 3025,0 | 55,9 | 2,9 | 8,2 | 0,051 | 8,3 | |
| 54,3 | 47,2 | 2563,0 | 2227,8 | 2948,5 | 56,2 | -9,0 | 80,9 | 0,160 | 12,9 | |
| 49,3 | 55,2 | 2721,4 | 3047,0 | 2430,5 | 58,0 | -2,8 | 7,8 | 0,048 | 73,7 | |
| Итого | 405,2 | 384,3 | 22162,3 | 21338,4 | 23685,8 | 210,3 | 0,646 | 230,47 | ||
| Ср. знач. | 57,9 | 54,9 | 3166,0 | 3048,3 | 3383,7 | 30,05 | 0,092 | 32,924 |


Также для определения параметров уравнения можно воспользоваться встроенной функцией категории «Статистические» → «ЛИНЕЙН». Подробнее об использовании этой функции см. Приложение 3.
Таким образом, по формуле (3) мы получили следующее уравнение парной линейной регрессии:

Вывод: при увеличении доходов на 1 млн. руб. доля расходов на потребление продуктов питания снижается на 0,36 %.
Оценим тесноту связи между фактором и результатом с помощью линейного коэффициент корреляции 
(14), (9), (17):





Вывод: связь обратная, слабая. При увеличении доходов потребление снижается с невысокой вероятностью.
3) На этапе верификации оценим качество модели. Для этого рассчитаем коэффициент детерминации, F-критерий, t-статистику.
Рассчитаем коэффициент детерминации по формуле (15), (16) и (17) или воспользуемся встроенной функцией категории «Статистические» → «ЛИНЕЙН»:

Вывод: уравнение объясняет всего 12,5% вариации результата
Рассчитаем F-критерий по формулам (19) и (21) или воспользуемся встроенной функцией категории «Статистические» → «ЛИНЕЙН»:

Определим Fтабл по таблице Приложения 1. Степени свободы числителя и знаменателя определим по таблице 2 (стр10). Число наблюдений – 7, параметр при х один – это b. Таким образом, k1 = 1, k2 = 5.
Рассчитаем t-статистику для каждого параметра по формулам (22)-(28) или воспользуемся встроенной функцией категории «Статистические» → «ЛИНЕЙН»:



Определим tтабл для 5 степеней свободы и вероятности 0,95 по таблице Приложения 3. При поиске табличного значения учтем, что t-критерий симметричен относительно оси х, поэтому сравниваем значения фактические и табличные по модулю.
Вывод: 
меньше tтабл следовательно с вероятностью 95% гипотеза о статистической незначимости параметров r и b принимается.
В свою очередь, 
больше tтабл следовательно с вероятностью 95% гипотеза о статистической незначимости параметра а отклоняется.
4) прогнозирование: оценим уровень потребления при заданной заработной плате 58,0 млн. руб. на доверительном интервале с заданной вероятностью по формулам (30) и (31).
Для нахождения 
подставим в уравнение связи заданное значение х:

%.
Вывод: при уровне заработной платы на уровне 58 млн. руб. доля расходов на потребление составит 54,86 %.
Для повышения надежности прогноза определим доверительный интервал прогноза по формулам (30) и (31).
Стандартную ошибку прогноза 
определим по формуле (32) или воспользуемся встроенной функцией категории «Статистические» → «ЛИНЕЙН»:

Тогда среднюю ошибку прогноза определим по формуле (30). Для этого самостоятельно зададим требуемый уровень надежности (90%, 95% или 99%) и по таблице Приложения 2 для 5 = 7 – 2 степеней свободы определим tтабл. Пусть уровень надежности равен 90%, тогда tтабл = 2,0150.

%.
Тогда границы доверительного интервала составят по формуле (30):
(54,86-13,07) % 2 ) воспользуемся функцией «Дополнительные параметры линии тренда» меню «Диаграмма», как на рисунке 3.

Рисунок 1.3 – Работа с диаграммой MS Excel
Не нашли то, что искали? Воспользуйтесь поиском:
Лучшие изречения: Да какие ж вы математики, если запаролиться нормально не можете. 8323 – 
| 7261 –  или читать все.
или читать все.
185.189.13.12 © xn----ctbetbqubfsc3c1hk.xn--p1ai Не является автором материалов, которые размещены. Но предоставляет возможность бесплатного использования. Есть нарушение авторского права? Напишите нам | Обратная связь.
Отключите adBlock!
и обновите страницу (F5)
очень нужно
Определение параметров уравнения парной регрессии
Важнейший частный случай стат. связи – корреляционная связь. При корреляц. связи разным значениям одной переменной соответствуют различные ср. значения др. переменной, т.е. с изменением значения признака х изменяется ср. значение признака у.
В статистике принято различать след. виды зависимости:
4. парная корреляция – связь между 2 мя признаками результативным и факторным, либо м-ду двумя факторными.
5. частная корреляция – зависимость м-ду результативным и одним факторным признаком при фиксир. значении др. факторного признака.
6. множественная корреляция – зависимость результат. признака от двух и более факторных признаков.
Уравнение парной линейной корреляционной связи называется уравнением парной регрессии и имеет вид 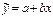
. Где 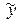 – ср. значение разультативного признака y, при определеных значениях признака x; a – свободный член уравнения; b – коэф-фициент регрессии, показывает вариацию приз-нака y, приходящуюся на единицу вариации x.
– ср. значение разультативного признака y, при определеных значениях признака x; a – свободный член уравнения; b – коэф-фициент регрессии, показывает вариацию приз-нака y, приходящуюся на единицу вариации x.
Параметры уравнения находятся с помощью метода наименьших квадратов. Исходным методом наименьших квадратов для прямой линии является следующее:
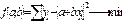
С помощью преобразований получаем систему нормальных уравнений:
Если первое уравнение системы разделить на n:
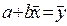
, откуда 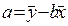
Для расчета параметра b используется формула:
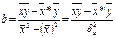
Коэффициент парной регрессии, обозначенный b имеет смысл показателя силы связи между показателями факторного признака x и вариаций результативного признака y. Положительный знак при коэффициенте регрессии говорит о прямой связи между признаками, знак «-» говорит об обратной связи между признаками.
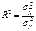
, где 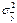 -дисперсия переменной у, а
-дисперсия переменной у, а 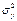 – общая дисперсия переменной у. Извлекая корень квадратный из
– общая дисперсия переменной у. Извлекая корень квадратный из 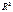 получим коэф-т множеств. корреляции у. Он должен быть не значение R, тем ближе оно к 1, тем лучше уравнение регрессии, тем надежнее рез-ты анализа или прогноза на его основе.
получим коэф-т множеств. корреляции у. Он должен быть не значение R, тем ближе оно к 1, тем лучше уравнение регрессии, тем надежнее рез-ты анализа или прогноза на его основе.
51. Оценка результатов корреляционно-регрессионного анализа.Важн. частный случай стат. связи – корреляционная связь. При корреляц. связи разным значениям одной переменной соотв-ют различные ср. значения др. переменной. Задачей корреляц. анализа явл. колич. оценка тесноты связи м-ду признаками. Регрессия исследует форму связи. З-ча регресс. анализа – опр-ние аналитич. выражения связи. Коррел- регресс. анализ включает в себя измерение тесноты связи и установления аналитич. выражения связи.
Показатели корреляц. связи, вычисленные по ограниченной совок-ти явл-ся лишь оценками той или иной законом-ти, поскольку в любом параметре сохраняется эл-т случайности. Поэтому необх-ма стат. оценка ст-ни точности и надежности пар-ров корреляции и регрессии. Надежность- вероят-ть того, что значение проверяемого парам-ра ≠0 и не включ-т в себя величины противопол-х знаков. Вероятностная оценка пар-ров корреляции произв-ся по общим правилам проверки стат. гипотез. В частности путем сравнения оцениваемой величины со ср. случайной ошибкой оценки. Для коэффиц-та парной регрессии(b) ср. ошибка оценки вычисл-ся по формуле: 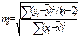
где y ¯ – знач-ния результ. признака, полученные по ур-нию регрессии; ∑(yi-y¯) 2 /(n-2)- остат. дисперсия; (n-2)- число степеней свободы
Зная ср. ошибку оценки коэф. регресии м. вычислить вер-ть того, что нулевое значение коэфф-та входит в интервал возможных с учетом ошибки значений. С этой целью нах-ся отн-ние коэф. к его ср. ошибке, называемое t-критерий Стьюдента: t=b/mb.
Если t расчетное > t табличного, то вероят-ть нулевого значения коэф. регрессии 0.05, то полученный рез-т- незначительный, 2 2 , то соотв. модель незначимая.После оценки значимости регресс. модели м. говорить, что значимы хотя бы 1или все коэф-ты регрессии.
Дата добавления: 2015-11-05 ; просмотров: 351 | Нарушение авторских прав
Парная регрессия. – Шпаргалки к экзамену – Эконометрия
Парной регрессией называется уравнение связи двух переменных
где у – зависимая переменная (результативный признак);
х – независимая, объясняющая переменная (признак-фактор).
Различают линейные и нелинейные регрессии.
Метод наименьших квадратов МНК
Для оценки параметров регрессий, линейных по этим параметрам, используется метод наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических значений ŷx при тех же значениях фактора x минимальна, т. е.

5. Оценка статистической значимости показателей корреляции, параметров уравнения парной линейной регрессии, уравнения регрессии в целом.


6. Оценка степени тесноты связи между количественными переменными. Коэффициент ковариации. Показатели корреляции: линейный коэффициент корреляции, индекс корреляции (= теоретическое корреляционное отношение).

Мч(у) – Т.е. получим корреляционную зависимость.
Наличие корреляционной зависимости не может ответить на вопрос о причине связи. Корреляция устанавливает лишь меру этой связи, т.е. меру согласованного варьирования.
Меру взаимосвязи му 2 мя переменными можно найти с помощью ковариации.
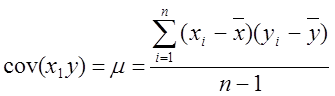
, 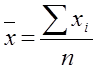 ,
, 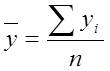
Величина показателя ковариации зависит от единиц в γ измеряется переменная. Поэтому для оценки степени согласованного варьирования используют коэффициент корреляции – безразмерную характеристику имеющую определенный пределы варьирования..
7. Коэффициент детерминации. Стандартная ошибка уравнения регрессии.
Коэффициент детерминации (rxy2) – характеризует долю дисперсии результативного признака y, объясняемую дисперсией, в общей дисперсии результативного признака. Чем ближе rxy2 к 1, тем качественнее регрессионная модель, то есть исходная модель хорошо аппроксимирует исходные данные.

8. Оценка стат значимости показателей корр-ии, параметров уравнения парной линейной регрессии, уравнения регрессии в целом: t-критерий Стьюдента, F-критерий Фишера.
9. Нелинейные модели регрессии и их линеаризация.
Нелинейные регрессии делятся на два класса: регрессии, нелинейные относительно исключенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, и регрессии, нелинейные по оцениваемым параметрам.
Примеры регрессий, нелинейных по объясняющим переменным, но линейных по оцениваемым параметрам:

Нелинейные модели регрессии и их линеаризация
При нелинейной зависимости признаков, приводимой к линейному виду, параметры множественной регрессии также определяются по МНК с той лишь разницей, что он используется не к исходной информации, а к преобразованным данным. Так, рассматривая степенную функцию
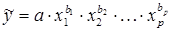
,
мы преобразовываем ее в линейный вид:
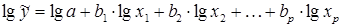
,
где переменные выражены в логарифмах.
Далее обработка МНК та же: строится система нормальных уравнений и определяются неизвестные параметры. Потенцируя значение 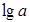
, находим параметр a и соответственно общий вид уравнения степенной функции.
Вообще говоря, нелинейная регрессия по включенным переменным не таит каких-либо сложностей в оценке ее параметров. Эта оценка определяется, как и в линейной регрессии, МНК. Так, в двухфакторном уравнении нелинейной регрессии
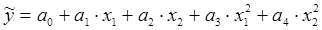
может быть проведена линеаризация, введением в него новых переменных 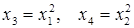
. В результате получается четырехфактороное уравнение линейной регрессии
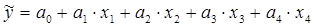
10.Мультиколлинеарность. Методы устранения мультиколлинеарности.
Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью. Наличие мультиколлинеарности факторов может означать, что некоторые факторы будут всегда действовать в унисон. В результате вариация в исходных данных перестает быть полностью независимой, и нельзя оценить воздействие каждого фактора в отдельности.
Чем сильнее мультиколлинеарность факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью метода наименьших квадратов (МНК).
Включение в модель мультиколлинеарных факторов нежелательно по следующим причинам:
ü затрудняется интерпретация параметров множественной регрессии; параметры линейной регрессии теряют экономический смысл;
ü оценки параметров ненадежны, обнаруживают большие стандартные ошибки и меняются с изменением объема наблюдений, что делает модель непригодной для анализа и прогнозирования

Методы устранения мультиколлинеарности
– исключение переменной (ых) из модели;
Однако нужна определенная осмотрительность при применении данного метода. В этой ситуации возможны ошибки спецификации.
– получение дополнительных данных или построение новой выборки;
Иногда для уменьшения мультиколлинеарности достаточно величить объем выборки. Например, при использовании ежегодных данных можно перейти к поквартальным данным. Увеличение количества данных уменьшает дисперсии коэффициентов регрессии и тем самым увеличивает их статистическую значимость. Однако получение новой выборки или расширение старой не всегда возможно или связано с серъезными издержками. Кроме того, такой подход может увеличить
– изменение спецификации модели;
В ряде случаев проблема мультиколлинеарности может быть решена путем изменения спецификации модели: либо меняется форма модели, либо добавляются новые объясняющие переменные, не учтенные в модели.
– использование предварительной информации о некоторых параметрах;
11.Классическая линейная модель множественной регр-ии (КЛММР). Определение параметров ур-я множественной регр-ии методом наим квадратов.
Параметры уравнения парной регрессии
Параметры уравнения y = a*x + b
а) с помощью статистической функции ЛИНЕЙН (Excel). Получаем следующую статистику:
| a | 0,15 | 197,80 | b |
| ma | 0,07 | 13,77 | mb |
| R 2 | 0,32 | 8,36 | Sост |
| Fф | 5,07 | 11 | Ч.С.С |
| 354,56 | 768,52 | (y-y x ) 2 |
Записываем уравнение парной линейной регрессии:
Экономический смысл уравнения: с увеличением х на 1 ед., y возрастает в среднем на а ед.
Если требуется рассчитывать без применения Excel, то строим таблицу.
| N | x | y | x 2 | x*y | (y-y x ) 2 | (y-y ср ) 2 |
| 1 | ||||||
| 2 | ||||||
| 3 | ||||||
| N | ||||||
| Итого | ||||||
| Среднее |
б) для парной линейной регрессии:
в) или решая систему уравнений
Для автоматического расчета можно воспользоваться сервисом Уравнение регрессии
б) с помощью статистической функции КОРРЕЛ (Excel)
в) по формуле:
или
К xy – корреляционный момент (коэффициент ковариации)
Средняя ошибка аппроксимации (рассчитываем столбцы y x , y i -y x , A i )
Это означает, что в среднем, расчетные значения зависимого признака отклоняются от фактического значения на А%.
а) с помощью функции ЛИНЕЙН (Excel)
б) R 2 = r 2 xy ; R 2 = 0,32, т.е. в 31,57% случаев изменения х приводят к изменению y . Другими словами – точность подбора уравнения регрессии 31,57% – низкая.
Оценка статистической значимости
а) по критерию Фишера :
1. Выдвигаем нулевую гипотезу о статистической незначимости параметров регрессии и показателя корреляции а = b = r xy
2. Фактическое значение критерия получено из функции ЛИНЕЙН (Excel)
3.Для определения табличного значения критерия рассчитываем коэффициенты k1 = m = 1 и k2= n – m – 1
4. Сравниваем фактическое и табличное, значения критерия F факт > F табл
нулевую гипотезу отклоняем и делаем вывод о статистической значимости и надежности полученной модели.
б) по критерию Стъюдента
1. Выдвигаем нулевую гипотезу о статистически незначимом отличии показателей от нуля; а = b = r xy =0;
2. Табличное значение t-критерия зависит от числа степеней свободы и заданного уровня значимости а.
Уровень значимости – это вероятность отвергнуть правильную гипотезу при условии, что она верна.
3. Фактические значения t-критерия рассчитываются отдельно для каждого параметра модели. С этой целью, сначала определяются случайные ошибки параметров ma, mb, mr
S 2 – необъясненная дисперсия является несмещенной оценкой дисперсии случайных отклонений
n – число наблюдений, m – число независимых переменных.
Рассчитаем фактические значения t-критерия.
4. Сравниваем фактические значения t-критерия с табличными значением:
нулевую гипотезу отклоняем, параметры a = b = r xy – не случайно отличаются от нуля и являются статистически значимыми и надежными.
в) чтобы рассчитать доверительный интервал для параметров регрессии a,b необходимо определить предельную ошибку параметров:
а ± ∆a; a – ∆a ≤ a ≤ a + ∆a
b ± ∆b; b – ∆b ≤ b ≤ b + ∆b
Анализ верхней и нижней границ доверительного интервалов показывает, что с вероятностью р = 1- α = 0,95 параметры а и b не принимают нулевые значения, т.е. являются статистически значимыми и надежными. Если одна из границ доверительного интервала – меньше нуля или равна нулю – делается вывод о статистической незначимости соответствующего параметра.
4. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Прогнозное значение yp определятся путем подстановки в уравнение регрессии соответствующего прогнозного значения хр. Если прогнозное значение составит хр = ∙1,1, то прогнозное значение y
5. Рассчитаем случайную ошибку прогноза:
Предельная ошибка прогноза: ∆y = tтабл*myp
Доверительный интервал прогноза:
С надежностью 0,95 прогнозное значение y заключено в данном доверительном интервале. Поскольку границы не принимают нулевых значений можно сделать вывод о статистической надежности прогноза.
Автоматический расчет
Для автоматического расчета можно воспользоваться сервисом Уравнение регрессии. Необходимо будет ввести значения x,y (можно вставить из MS Excel). Решение оформляется в файле MS Word с пояснением нахождения каждого параметра.

Позвольте представиться. Меня зовут Татьяна. Я уже более 8 лет занимаюсь психологией. Считая себя профессионалом, хочу научить всех посетителей сайта решать разнообразные задачи. Все данные для сайта собраны и тщательно переработаны для того чтобы донести как можно доступнее всю необходимую информацию. Перед применением описанного на сайте всегда необходима ОБЯЗАТЕЛЬНАЯ консультация с профессионалами.










